Text Data Cleaning And Pre-processing Techniques
First, you'll explore the fundamental characteristics of textual data and learn to identify common issues such as noise and missing data.
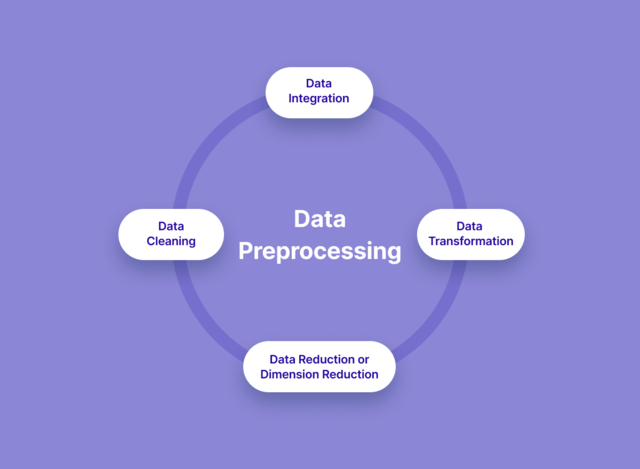
Next, you'll discover techniques for cleaning and handling missing data, along with basic noise removal strategies.
Finally, you'll learn how to utilize advanced text pre-processing techniques, including text normalization, tokenization, and handling special characters and emojis.
When you're finished with this course, you'll have the skills and knowledge of text data pre-processing needed to enhance the quality and reliability of your NLP models.
Bạn sẽ học được những gì?
- Cleaning and pre-processing text data is often the first and most crucial step in NLP. In this course, Text Data Cleaning and Pre-processing Techniques, you'll gain the ability to transform raw text into a clean, structured format ready for analysis.





